
I was reminded recently of a question that had been in the back of my mind when I was working at Twitter. With the exception of very old content, IDs of tweets and other entities like users are so-called “snowflake IDs” – unique timestamped integer IDs, constructed specifically to try and avoid ID collisions in a high volume application. Snowflake IDs use a certain number of bits for the timestamp, some bits to identify the ID generator from which the value came, and a set of bits for a “sequence number”, to disambiguate IDs that are generated within the same timestamp.
If you have a set of IDs generated using this scheme, you might notice that, in practice, many of the bits have the same value across IDs. For example, there is a limited number of ID generator hosts in use – you might only see a handful of different values, in practice. Most of the ID generator bits in your IDs are going to match, or perhaps only a couple of them might vary at all. The sequence numbers demonstrate the same sort of concentration – most of the time, the sequence number will be 0, since it is rare to generate many IDs within the timestamp resolution, and that 0 across lots of IDs would compress very well. And even the timestamps themselves will have many common values across a block of IDs, given the limited time windows in which services that use these formats have been operating. There just seems to be a lot of commonality across ID values, inherent to the format itself.
The question that I had asked myself was, how much could you compress these ID values, if you performed a bitwise transpose on the ID values (like BitShuffle), before compressing them? And how would this compare to just naively compressing these blocks of IDs with something like Brotli? It seemed to me that, after transposing the ID values, you might end up with very long runs of bits that all have the same value, which would be a great target for compression algorithms.
I spent a little time writing an experimental harness in F# to allow me to test this idea, and collect data about the effectiveness of applying different filters or conditioning techniques on the data, before compressing it. As configured out of the box, it runs 5000 trials, generating 3200 IDs per trial and running them through each of a set of data processing pipelines. I’ve put the code up on GitHub, along with a spreadsheet with graphs illustrating the effectiveness of each method from a run I did locally.
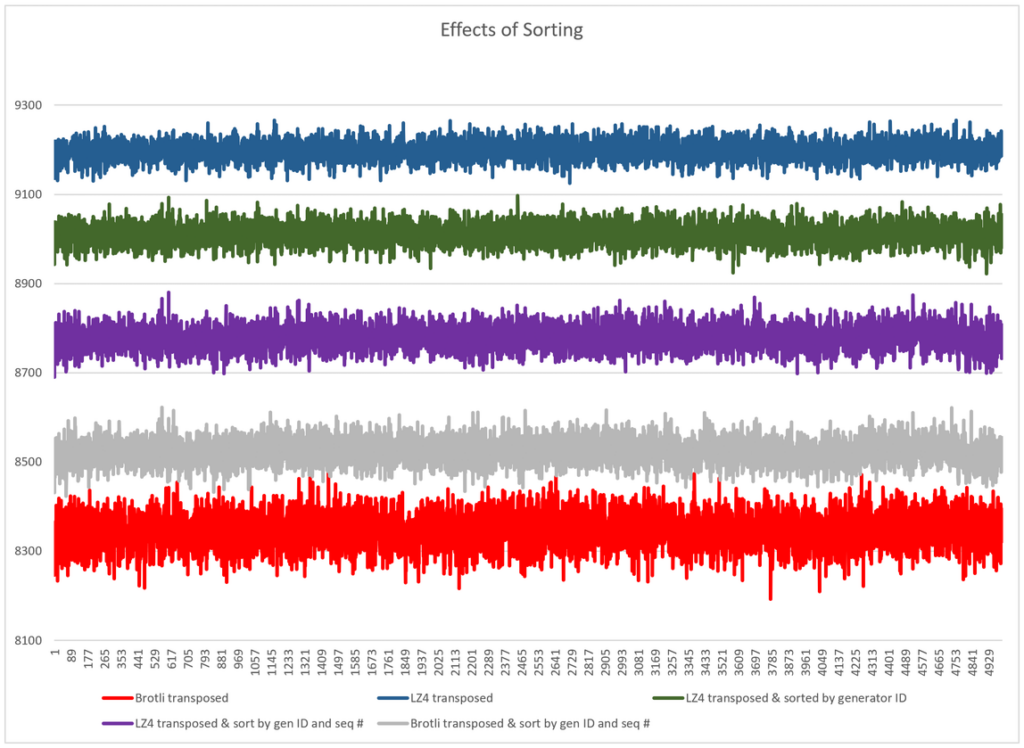
A quick summary of the results:
- General-purpose compression algorithms like Brotli perform well when compressing this data, even without any other conditioning applied to it.
- Performance-oriented algorithms like LZ4 produce significantly larger (60-100%) results than, say, Brotli, when no data conditioning is performed. Compared with uncompressed data, LZ4 compression without any further data conditioning only results in a ~35% space savings.
- The bitwise transposition technique works well for the algorithms like Brotli, reducing the size of the final data by another 15% or so. But it makes a huge difference for LZ4 and the like, cutting the size of the final data by another 45% or so, and putting it within 10% of the size of Brotli-compressed data.
- Grouping IDs by their generator ID and sequence numbers before applying the transpose results in another ~5% improvement in the final size of the LZ4-compressed data. As you can see in the graph above, this grouping change actually made Brotli compression significantly worse than with transposition alone, which is interesting.
- There didn’t seem to be any significant difference in changing the sort direction of the IDs in the block.
- Compared to the uncompressed data, “Brotli with transpose” reduced the size of the ID data by ~66%. “LZ4 with grouping and transpose” reduced the size of the ID data by ~65.7%.
These results suggest quite strongly that proper data conditioning before applying compression to snowflake IDs can result in pretty big space savings, on the order of ~66%. And if you’re using an algorithm like LZ4, you’ll definitely want to transpose your ID values before compression. If you have large sets of IDs like this in your system, either at rest, or as part of calls or messages in your system, it might be worth trying these techniques to reduce data size.
If you’re interested in playing around with the parameters of this test, you can easily tweak them in the source, and re-run it again locally. You can also try configuring your own data conditioning and compression pipeline, and compare it against the ones that are already there.





{kind=link}